Linux下搭建Spark 的 Python 编程环境的方法
Spark编程环境
Spark 可以独立安装使用,也可以和Hadoop 一起安装使用。在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本。
Spark 安装
访问 Spark 下载页面 ,并选择最新版本的 Spark 直接下载,当前的最新版本是 2.4.2 。下载好之后需要解压缩到安装文件夹中,看自己的喜好,我们是安装到了 /opt 目录下。
tar -xzf spark-2.4.2-bin-hadoop2.7.tgz mv spark-2.4.2-bin-hadoop2.7/opt/spark-2.4.2
为了能在终端中直接打开 Spark 的 shell 环境,需要配置相应的环境变量。这里我由于使用的是 zsh,所以需要配置环境到 ~/.zshrc 中。
没有安装 zsh 的可以配置到 ~/.bashrc 中
# 编辑 zshrc 文件 sudo gedit ~/.zshrc # 增加以下内容:export SPARK_HOME=/opt/spark-2.4.2export PATH=$SPARK_HOME/bin:$PATH export <a href="https://www.linuxidc.com/topicnews.aspx?tid=17" target="_blank" title="Python">Python</a>PATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
配置完成后,在 shell 中输入
spark-shell 或者 pyspark 就可以进入到 Spark 的交互式编程环境中,前者是进入 Scala 交互式环境,后者是进入 Python 交互式环境。配置 Python 编程环境
在这里介绍两种编程环境, Jupyter 和 Visual Studio Code。前者方便进行交互式编程,后者方便最终的集成式开发。
PySpark in Jupyter
首先介绍如何在 Jupyter 中使用 Spark,注意这里 Jupyter notebook 和 Jupyter lab 是通用的方式,此处以 Jupyter lab 中的配置为例:
在 Jupyter lab 中使用 PySpark 存在两种方法:
pyspark 将自动打开一个 Jupyter lab;
findSpark 包来加载 PySpark。
第一个选项更快,但特定于Jupyter笔记本,第二个选项是一个更广泛的方法,使PySpark在你任意喜欢的IDE中都可用,强烈推荐第二种方法。
方法一:配置 PySpark 启动器
更新 PySpark 启动器的环境变量,继续在 ~/.zshrc 文件中增加以下内容:
export PYSPARK_DRIVER_PYTHON=jupyter export PYSPARK_DRIVER_PYTHON_OPTS='lab'
如果要使用 jupyter notebook,则将第二个参数的值改为 notebook
刷新环境变量或者重启机器,并执行 pyspark 命令,将直接打开一个启动了 Spark 的 Jupyter lab。
pyspark

方法二:使用 findSpark 包
在 Jupyter lab 中使用 PySpark 还有另一种更通用的方法:使用
findspark 包在代码中提供 Spark 上下文环境。findspark 包不是特定于 Jupyter lab 的,您也可以其它的 IDE 中使用该方法,因此这种方法更通用,也更推荐该方法。
首先安装 findspark:
pip install findspark之后打开一个 Jupyter lab,我们在进行 Spark 编程时,需要先导入 findspark 包,示例如下:
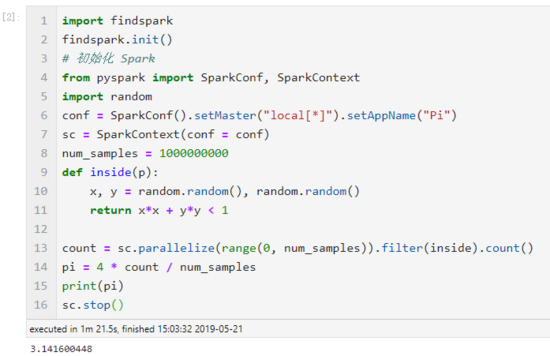
# 导入 findspark 并初始化import findspark
findspark.init()from pyspark importSparkConf,SparkContextimport random
# 配置 Spark
conf =SparkConf().setMaster("local[*]").setAppName("Pi")# 利用上下文启动 Spark
sc =SparkContext(conf=conf)
num_samples =100000000definside(p):
x, y = random.random(), random.random()return x*x + y*y <1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi =4* count / num_samples
print(pi)
sc.stop()
运行示例:
PySpark in VScode
Visual Studio Code 作为一个优秀的编辑器,对于 Python 开发十分便利。这里首先推荐个人常用的一些插件:
Python:必装的插件,提供了Python语言支持;
Code Runner:支持运行文件中的某些片段;
此外,在 VScode 上使用 Spark 就不需要使用 findspark 包了,可以直接进行编程:
from pyspark importSparkContext,SparkConf
conf =SparkConf().setMaster("local[*]").setAppName("test")
sc =SparkContext(conf=conf)
logFile ="file:///opt/spark-2.4.2/README.md"
logData = sc.textFile(logFile,2).cache()
numAs = logData.filter(lambda line:'a'in line).count()
numBs = logData.filter(lambda line:'b'in line).count()print("Lines with a: {0}, Lines with b:{1


