分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控(推荐)
服务器磁盘的运作情况在一定程度上反应系统的负载。
磁盘通常是服务器最慢的设备,极容易出现瓶颈,通过监控可以判断出整个系统的短板。
zabbix并没有给我们提供这么一个模板来完成在Linux中磁盘IO的监控,所以我们需要自己来创建一个,在此还是在Linux OS中添加。
由于一台服务器中磁盘众多,如果只一两台可以手动添加,但服务集群达到几十那就非常麻烦,因此需要利用自动发现 这个功能,自动发现后自动添加对服务器磁盘的监控,而且添加磁盘后也会自动添加到监控,实现自动化运维的效果,所以在这里也演示一次自动发现的配置。
打开Linux模板,添加自动发现规则

上面的key值是需要在 zabbix_agent.conf 中配置的
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh
自动发面的规则用shell代码实现,返回一段磁盘的json list

代码 disk_discovery.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg]\b|\bxvd[abcdefg]\b"|grep -i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf '\n\t\t{'
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
到此自动发现磁盘已完,有点简单吧。
添加监控项
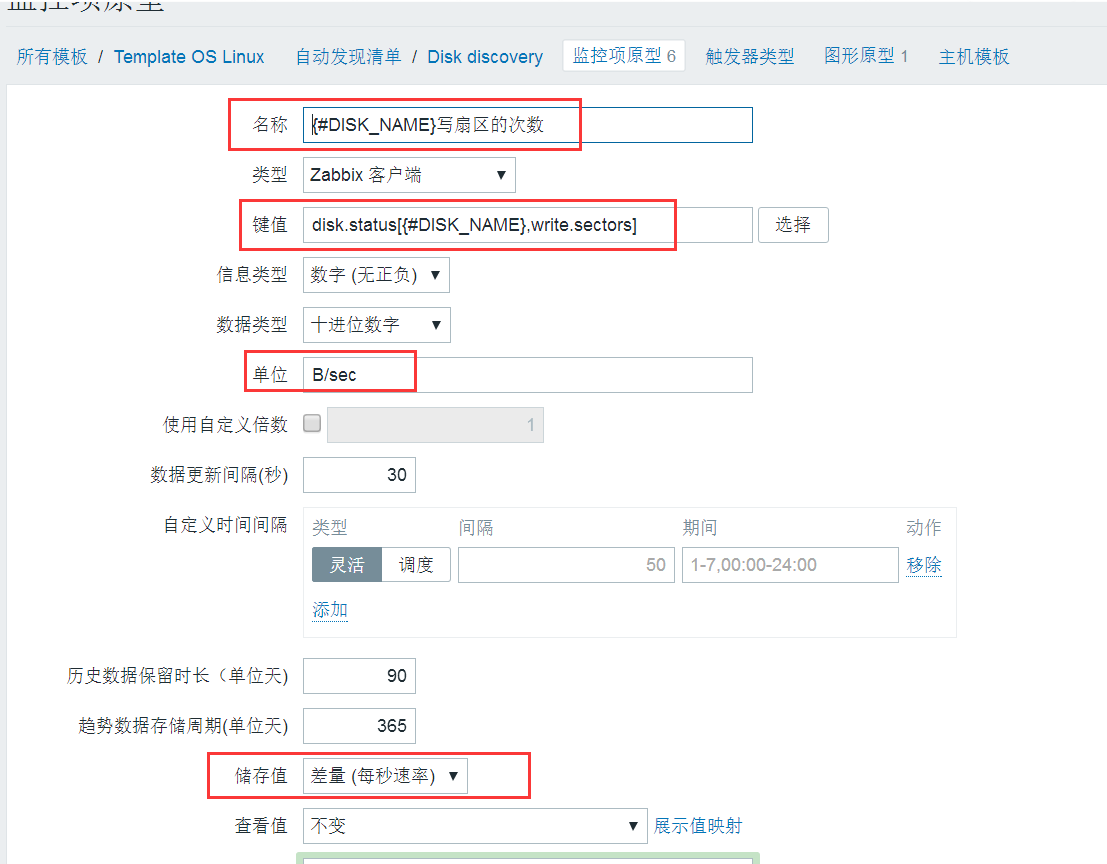
按照上面的内容添加第一个写扇区的次数监控,接下来按下面的内容添加共6个内容。

内容介绍
名称: {#DISK_NAME}磁盘读的次数
键值: disk.status[{#DISK_NAME},read.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的次数
键值: disk.status[{#DISK_NAME},write.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘读的毫秒数
键值: disk.status[{#DISK_NAME},read.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的毫秒数
键值: disk.status[{#DISK_NAME},write.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}读扇区的次数
键值: disk.status[{#DISK_NAME},read.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
名称: {#DISK_NAME}写扇区的次数
键值: disk.status[{#DISK_NAME},write.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
然后如果得到这些值是需要shell脚本的:
disk_status.sh
#/bin/sh
device=$1
DISK=$2
case $DISK in
read.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $4}' #//磁盘读的次数
;;
read.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $7}' #//磁盘读的毫秒数
;;
write.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $8}' #//磁盘写的次数
;;
write.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $11}' #//磁盘写的毫秒数
;;
io.active)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $12}' #//I/O的当前进度,
;;
read.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $6}' #//读扇区的次数(一个扇区的等于512B)
;;
write.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $10}' #//写扇区的次数(一个扇区的等于512B)
;;
io.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $13}' #//花费在IO操作上的毫秒数
;;
esac
在客户端中的zabbix_agent.conf 中一起配置:
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh UserParameter=disk.status[*],/usr/local/share/zabbix/alertscripts/disk_status.sh $1 $2
要注意的是以上两个文件需要给x 执行权限。
添加图形显示
在图形原型中添加,注意名称中要带哪个磁盘的动态名称,不然会出现Disk IO 已注册的错误信息。
zabbix3 Cannot create graph: graph with the same name "Disk IO" already exists
在监控项中选择上面添加的6个监控项。

测试效果
重启客户端的zabbix_agentd,然后在zabbix服务端对服务发现和写扇区次数进行测试。代码如下,有显示内容说明已经部署成功。


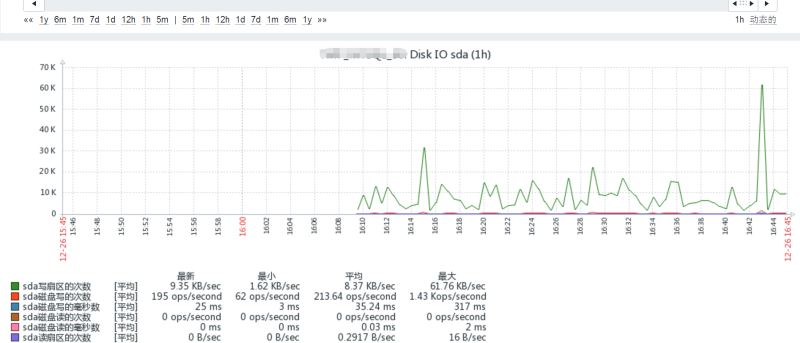
查看图形化,选择监控主机,图形中查看,若还没有项,需要等个几分钟再看。
问题:
网上有网友用的是python来实现自动发现功能,但测试发现老是报错:
python import: command not found

可能是依赖包有问题,考虑到集群服务器的python环境问题,因此就不考虑用python的实现。


